
In an October 2019 paper published in IUCrData, researchers unveiled a crystalline form of the psilocybin derivative 4-HO-DPT (4-hydroxy-N,N-di-n-propyltryptamine).1 This study builds on the work done by these researchers from CaaMTech and the University of Massachusetts earlier this year, in which they solved crystal structures for the N-isopropyl-N-methyl derivatives of DMT (dimethyltryptamine) and psilocin,2 and two crystal structure forms of 4-AcO-DMT (psilacetin).3,4
For comparison, Figure 1 shows the 2D chemical structure of 4-HO-DPT and Figure 2, the crystal structure of the salt solved in the Chadeayne et al. study. The authors describe the new salt as:
…a singly protonated DPT cation, one half of a fumarate dianion (completed by a crystallographic centre of symmetry) and two water molecules of crystallization in the asymmetric unit.
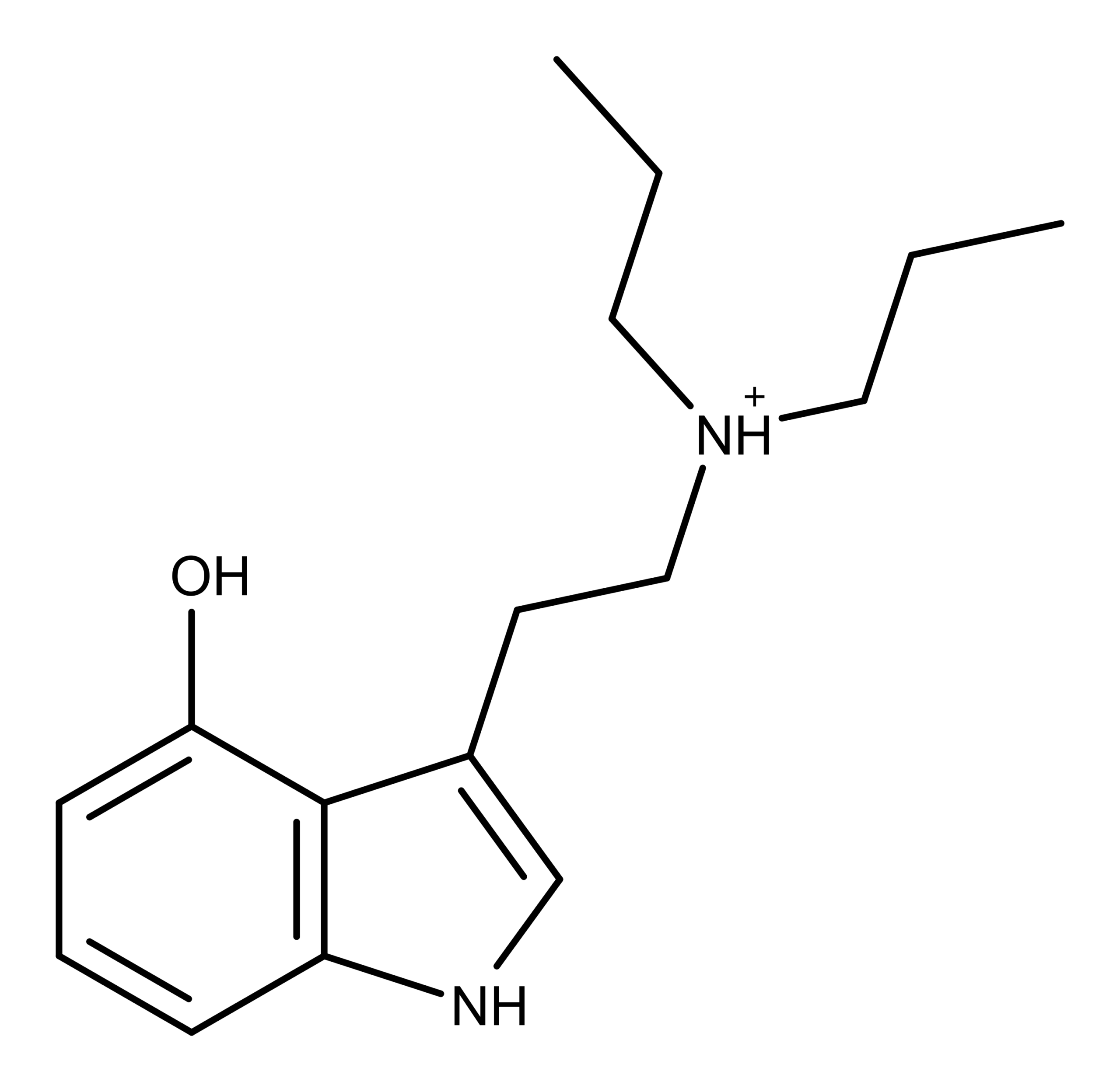
Figure 1: The chemical structure of 4-HO-DPT.
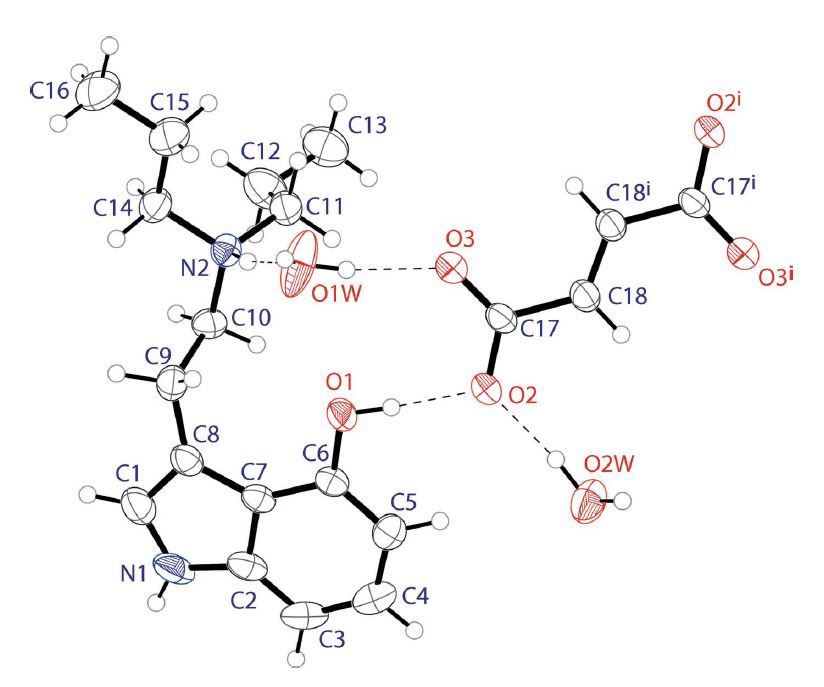
Figure 2: The molecular structure of bis(4-hydroxy-N,N-di-n-propyltryptammonium) fumarate tetrahydrate.1
The new solvate form of 4-HO-DPT shown in Figure 2 far surpasses the 2D structure in Figure 1 in terms of detail and its actual chemical structure. Conclusively solving the crystal structure, opens to door to understanding its physical properties, and testing of its activity at biological receptors.
What is 4-HO-DPT?
4-HO-DPT is a psilocybin derivative and a structural homologue of psilocin. It is a synthetic compound that is not known to occur in nature. However, in 1990, mushroom researcher Jochen Gartz patented a method for adding DPT to mushroom growth medium which resulted in the mushroom fruiting bodies containing 4-HO-DPT.5
Repke et al. were first to report the synthesis of 4-HO-DPT in 1977.6 Alexander and Ann Shulgin documented their synthesis of it (#20 in TiHKAL), and describe a 20 mg oral dose as “Possible threshold, nothing more.” 7
Learning About the Chemistry of 4-HO-DPT
Prior to the current results published by Chadeayne et al. in IUCrData, virtually nothing was known about 4-HO-DPT. There has been no research interest in it, and this compounded by the fact that it is difficult to synthesize in the lab. Nevertheless, solving its crystal structure (and that of other bioactive tryptamine molecules) is a pioneering step because it defines the physical identity of 4-HO-DPT. Characterizing this fundamental structure is essential for all downstream research, such as structure-activity relationships that define the biological and clinical properties of the molecule. Understanding these relationships is key to developing effective drugs.
Why Solve Crystal Structures of Compounds?
It is important to remember that small changes at the molecular level can translate into significant changes in effect when it comes to drugs. Therefore, working with compounds at the molecular level is essential for unraveling the mysteries of how drugs work and how other compounds affect them. The new crystalline form of 4-HO-DPT elucidated by Chadeayne et al. could be used to modulate the effects of each compound in a drug formulation (the entourage effect). In addition, determining the crystal structures of compounds is critical for understanding their physical properties and for probing their activity at receptors (e.g., modeling studies).
The Importance of Crystal Structures and Dosing
Crystal structures (aka solid-state structures) bring up an essential concept for consideration when it comes to dosing psychedelic compounds. Salt forms of compounds have a different molecular weight than just the compound itself. This affects the amount of the compound present in a given weight. Using the Chadeayne et al. study as an example, the crystal structure they solved for 4-HO-DPT has four molecules of water. This tetrahydrate form has a higher molecular weight. On top of this, the crystal form will have different chemical properties, and as a result, different pharmacological properties than 4-HO-DPT alone. Therefore, for accurate and precise dosing, it is vital to know the salt form of the psychedelic compound.

Barbara E. Bauer, MS
Barb is the former Editor and one of the founders of Psychedelic Science Review. She is currently a contributing writer. Her goal is making accurate and concise psychedelic science research assessable so that researchers and private citizens can make informed decisions.